전위, 중위, 후위 표기식 (prefix, infix, postfix notation)
전위, 중위, 후위 표기식 또는 전위, 중위, 후위 표기법이라고도 부른다. 그렇다면 이게 과연 무엇일까?
우리가 초등학교부터 배웠던 흔히 알고 있는 식, 예를 들어 A + B * C 같은 식을 중위 표기식이라고 한다. +, -, *, / 같은 사칙 연산의 기호가 숫자의 사이에 있어서 연산자의 우선순위에 따라 연산을 진행하는 방식이다. 요컨대 * 나 / 가 먼저 나오면 +, - 보다 우선적으로 연산을 하는 것이다. 그렇다면 전위 표기식과 후위 표기식은 무엇일까? 중위 표기식이 연산자가 숫자 사이에 있는 것이라면, 전위 표기식은 연산자가 수의 앞에, 후위 표기식은 연산자가 수의 뒤에 배치되는 것을 의미한다고 예상할 수 있다. 이것을 좀 더 자세히 알아보자.
전위 표기식
예를 들어 (A + B) - C * D 이 식의 연산 순서는 어떻게 될까? 초등학교 때 " * 와 / 는 + 나 - 보다 먼저 연산을 해준다." 라고 배웠을 것이다. 이것을 괄호를 이용해서 연산 순서를 정한다면 ((A + B) - (C * D)) 가 될 것이다. 즉 이미 괄호가 있던 A + B를 한 다음에, 연산 우선 순위가 높은 C * D를 한 후, 두 식을 빼주는 것이 옳은 순서가 된다. 전위 표기식은 연산자를 앞으로 보내서 아래와 같이 쓰게 된다.
-(+(AB) *(CD))
"뒤에 두 수를 앞에 있는 연산자로 연산을 하라" 라는 의미가 되는 것이다. 따라서 중위 표기식을 전위 표기식으로 바꾸는 방법은 아래와 같다.
- 연산의 우선순위에 따라 괄호를 이용해 묶어준다.
- 괄호 안의 연산자를 괄호 왼쪽 밖으로 이동시켜준다.
- 괄호를 제거해 준다.
후위 표기식
후위 표기식도 전위 표기식과 내용은 같다. 다만 전위 표기식이 연산자를 앞으로 보낸 것과는 반대로, 괄호의 오른쪽 밖으로 보내는 것이다. 위의 식 (A + B) - C * D을 후위 표기식으로 바꿔 본다면 아래와 같이 쓰게 된다.
((AB)+(CD)*)-
위에서 마지막 단계가 괄호를 제거하는 것이라고 했는데, 사실 해도 그만, 안 해도 그만인 단계라, 하면 좋지만 중요한 건 연산자의 위치가 변한다는 것이다. 중위 표기식을 후위 표기식으로 바꾸는 방법은 전위 표기식과 큰 차이가 없으며 아래와 같이 하면 된다.
- 연산의 우선순위에 따라 괄호를 이용해 묶어준다.
- 괄호 안의 연산자를 괄호 오른쪽 밖으로 이동시켜준다.
- 괄호를 제거해 준다.
전위, 후위 표기식 구현 방법
사실 우리가 궁금한 건 이걸 어떻게 코딩을 하느냐일 것이다. 일단 무작정 코딩하기에 앞서, 어떤 아이디어를 이용해서 구현하는지부터 보도록 하자. 만약 아래 식을 위에서 배운 후위 표기식으로 바꾸라고 한다면 이렇게 생각했을 것이다.
A + B - C * (D + E)
"일단 A + B니까 AB+로 바꿔주고, C * (D + E)에서 D 와 E가 괄호로 묶여있으니까 이것을 먼저 연산해줘야 한다. 따라서 (DE)+로 바꿔줄 수 있고, 여기에 C를 곱해주므로 C(DE)+*로 바꿔준 후, 마지막으로 두 결과를 빼줘야 하니까 AB+C(DE)+*-로 바꿀 수 있겠구나."
그렇다면 이 생각을 어떻게 구체화시킬 수 있을까? 위의 생각에 중요한 포인트가 들어있다. 이 포인트를 잘 생각하면서 이제 후위 표기식으로 바꾸는 방법을 만들어보자.
- 연산은 * 와 /, + 와 - 순으로 연산해줘야 한다는 것.
- 괄호가 있다면 괄호부터 연산을 해야한다는 것.
1. 맨 앞에서부터 탐색하면서 숫자가 나오면 바로 바로 써준다.
2. '(' 가 나오면 스택에 push 한다.
'(' 도 연산자로 취급한다. 괄호가 나오면 스택에 있는 연산자의 우선순위가 어떻게 되든 간에 괄호 안의 연산부터 실행해야하기 때문에 그 경계를 구분해주기 위해 넣어준다.
3. '+' 나 '-' 연산자가 나오면 뒤의 숫자도 봐야하니까 어딘가에 저장을 해야하는데, 그 저장 장소를 스택으로 정한다. 이 때 스택에 저장하기 전에, 혹시 이전에 저장되어 있던 내용이 있다면 전부 pop 해주고 출력을 한 다음 현재 연산자를 push 해준다.
왜 이렇게 하느냐? 가령 A + B + C를 생각해보자. 숫자는 바로 써줘야하니까 A를 쓰고, + 연산자는 스택에 저장해준다. 이 때는 스택이 비어있으니까 저장만 하면 된다. 이번에는 B가 나왔으니까 여기까지 출력은 AB가 될 것이다. 이 때 + 연산자가 다시 나오는데, 현재 스택에 저장되어 있는 연산자는 A와 B를 더하는 + 연산자이다. 후위 표기식은 두 숫자를 출력하고 그 뒤에 연산자를 이어 붙이는 방식이므로 현재까지 출력된 AB 뒤에 스택에 저장되어 있던 AB의 연산자인 +를 출력해서 AB+를 만드는 것이다. 그 후 두번째 + 연산자를 스택에 저장하는 것이다. 그리고 숫자가 다시 나왔으므로 또 출력을 하면 AB+C가 될 것이고, 이제 스택에 저장되어 있던 모든 연산자를 다 pop해서 출력해주면 된다. 따라서 AB+C+가 될 것이다.
4. '*' 나 '/' 연산자가 나오면 스택의 맨 위가 다른 '*' 나 '/' 연산자가 아닐 때 까지 pop 해준 후, push 한다.
이것 또한 같은 이유인데, 이번에는 A + B * C 를 생각해보자. 위의 과정에 따라 AB가 출력되고 + 연산자가 스택에 저장되어 있는 것은 알 수 있을 것이다. 문제는 * 연산이다. 위에서 계속 말했지만 * 나 / 연산은 + 나 - 연산보다 우선되어야 한다. 즉 A + B를 하기 전에 B * C를 먼저 해야하는 것이며, 이것을 먼저 하게 될 경우 BC*가 먼저 출력이 되어야 한다. 따라서 스택에 저장되어 있던 + 연산자를 일단 무시하고 * 연산자를 push 한 후에, C 까지 출력한 ABC 이후 스택에서 다 pop해서 차례대로 출력하면 ABC*+가 되는 것이다. 즉, 이전의 연산자가 */ 보다 우선순위가 낮은 +- 라면 push만 해서 나중에 차례대로 뺄 때 */ 가 먼저나올 수 있도록 해준다.
그러나 A / B * C 같은 경우를 생각해보면, 이 때에는 / -> * 순으로 연산을 하기 때문에, 스택에 * 연산을 넣기 전에 AB/를 먼저 출력해줘야 하므로 기존에 스택에 있던 / 를 pop 하고 출력을 먼저 한 다음에 진행을 해줘야한다.
5. ')' 가 나오면 '(' 가 나올 때 까지 전부 pop 해서 출력해준다.
2번에서 말했듯이 괄호 안의 연산부터 끝내야하기 때문에 ( ) 안의 연산자를 우선적으로 처리해준다.
위의 방대한 내용이 후위 표기식으로 나타내는 아이디어이다. 저렇게 글로 써넣으면 이해하기 상당히 힘드니까 그림으로 보도록 하자.
 |
| 1. A를 문자열에 붙인다. |
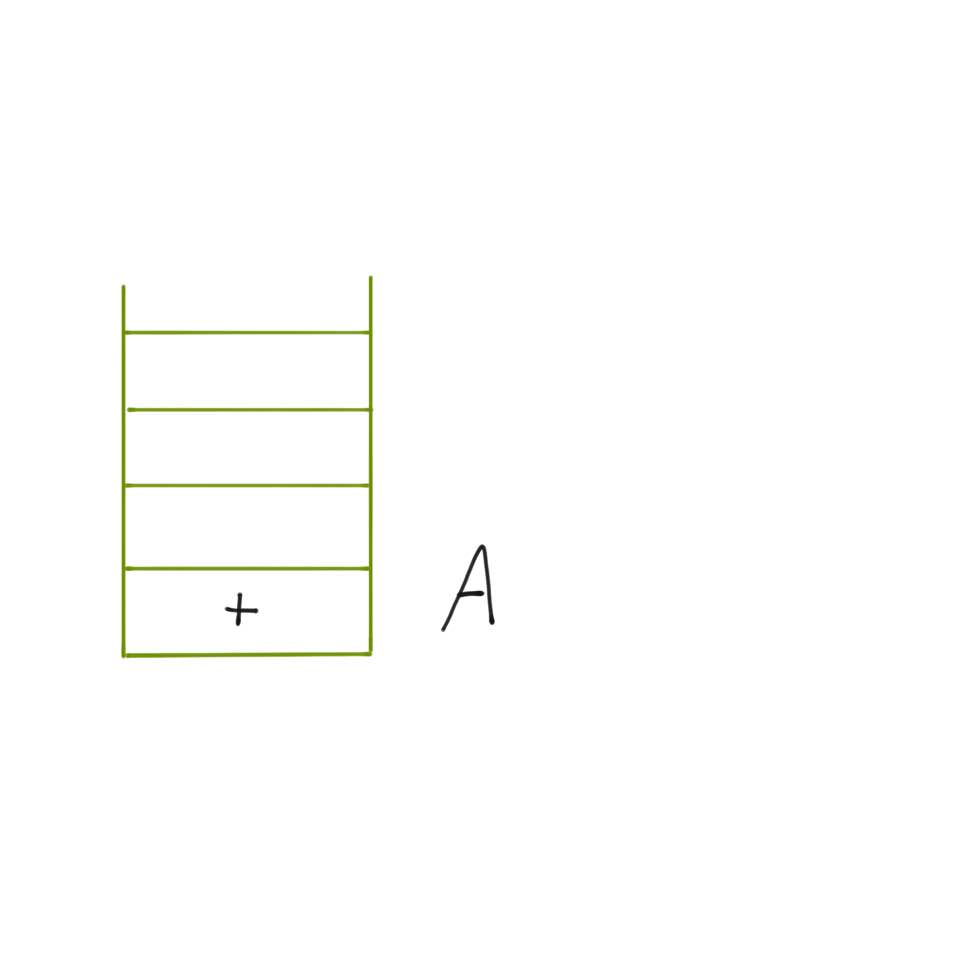 |
| 2. 스택이 비어있으므로 push 한다. |
 |
| 3. B를 문자열에 붙인다. |
 |
| 4. 스택에 있는 '+' 를 pop 한 후 push 한다. |
 |
| 5. 마찬가지로 C를 붙이고 *는 push한다. |
 |
| 6. 괄호 '(' 는 push 한다. |
 |
| 7. D, E는 문자열에 붙이고 +를 push한다. |
 |
| 8. ')' 가 나왔으므로 '(' 전까지 스택에 pop하면서 문자열에 붙인다. 그 후 '(' 는 pop한다. |
 |
| 9. 나머지도 pop 하고 문자열에 붙인다. |
전위 표기식도 아이디어는 같은데, 전위 표기식 같은 경우 연산자가 숫자의 앞에 가야하므로 출력을 거꾸로 해주면 된다. 즉, 뒤에서부터 탐색하면서 postfix를 적용시키면 된다.
#include <stdio.h> #include <iostream> #include <algorithm> #include <math.h> #include <vector> #include <queue> #include <set> #include <stack> #include <map> using namespace std; string postfix_notation(string s){ stack<char> op; string res = ""; for(int i = 0; i < s.size(); i++){ if(s[i] == ')'){ while(!op.empty() && op.top() != '('){ res += op.top(); op.pop(); } op.pop(); } else if(s[i] == '*' || s[i] == '/'){ while(!op.empty() && (op.top() == '*' || op.top() == '/') && op.top() != '('){ res += op.top(); op.pop(); } op.push(s[i]); } else if(s[i] == '+' || s[i] == '-'){ while(!op.empty() && op.top() != '('){ res += op.top(); op.pop(); } op.push(s[i]); } else if(s[i] == '('){ op.push(s[i]); } else{ res += s[i]; } } while(!op.empty()){ res += op.top(); op.pop(); } return res; } string prefix_notation(string s){ reverse(s.begin(), s.end()); for(int i = 0; i < s.size(); i++){ if(s[i] == '('){ s[i] = ')'; } else if(s[i] == ')'){ s[i] = '('; } } string prefix = postfix_notation(s); reverse(prefix.begin(), prefix.end()); return prefix; } int main(){ ios::sync_with_stdio(false); cin.tie(NULL); cout.tie(NULL); string s; cin >> s; cout << prefix_notation(s) << '\n'; cout << postfix_notation(s) << '\n'; return 0; }
출처 및 참고
댓글
댓글 쓰기